Tanzu Cluster Upgrade and Pod Security Admission
I was recently tasked with upgrading a Tanzu Kubernetes Cluster to v1.26.5 (version v1.26.5+vmware.2-fips.1 to be specific). Once I completed the upgrade, to my surprise, when I did a “kubectl get pods“, I found them to be missing. When i went digging for any known issues, I noticed something related to Pod Security that I had overlooked in the release notes.

Now, what does this mean and what will this do to my cluster workloads is what I attempt to clarify via this blog.
Pod Security Admission Controller
Pod Security Admission Controller or PSA is a replacement to the previously infamous Pod Security Policies (PSPs). The in-built PSA controller within a Kubernetes cluster helps implement Pod Security Standards, which are broadly categorised into the following 3 categories:
- Privileged – Complete permissions with no restrictions in place (implies privilege escalation)
- Baseline – Works with default pod configuration (restricts privilege escalation)
- Restricted – Fully restricted policy (follows Pod hardening settings)
To read further about pod security standards, you can use the upstream documentation. These pod security standards are applied/enforced to clusters via namespaces or via a cluster-wide configuration of the admission controller. Before we discuss about the how, we will look at the various enforcement modes available.
- enforce – Based on the security standard enforced, if there’s a violation pod will be rejected.
- audit – Even with violations, workloads aren’t impacted. But an audit event will be generated.
- warn – Even with violations, workloads aren’t impacted. But an user-facing warning is generated.
Enforcing Pod Security via Namespace Labels
To enforce the least privilege (Restricted) to users, nothing needs to be done, as this is the default setting with TKR 1.26 based clusters.
To enforce Baseline standards, admins can label the namespace with the following command:
kubectl label --overwrite ns NAMESPACE pod-security.kubernetes.io/enforce=baselineDoing so would allow them to run their pods with minimal security restrictions and with enforce=privileged they can run without any security restrictions, which might not be recommended in case of a heavily scrutinised environment.
Note: You can also do a “kubectl label ns –all pod-security.kubernetes.io/enforce=baseline” to apply this setting to all namespaces within the cluster.
Enforcing Pod Security via Cluster-wide Configuration
To enforce this across the cluster, we will have to edit the kube-apiserver configuration. SSH into the master node of your Guest cluster using the procedure mentioned here. To retrieve the login password, you can use the procedure mentioned here.
Once you are logged in to your master node, execute the following command to identify which file is being used for the pod security admission controller configuration.
cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep -i admission-control-config
cat /etc/kubernetes/extra-config/admission-control-config.yaml
You can update the defaults section to enforce: “baseline” or enforce: “privileged” based on your needs and restart the kube-apiserver.
Note: kube-apiserver runs as a static pod on your control plane nodes. Hence this change needs to be applied across all the control plane nodes that form your cluster deployment. Using the “kubectl label ns –all” is an easier option in my opinion 😀
Upgrade Scenario
Coming back to the case of upgrades, I upgraded my cluster from 1.25.7 to 1.26.5 without doing any of the aforementioned configuration changes. And here’s what happened.
Prior to upgrade

As you can see from the output, with v1.25.7, when I create a pod that violates the security standard, it throws me a warning, but still allows me to create the pod.
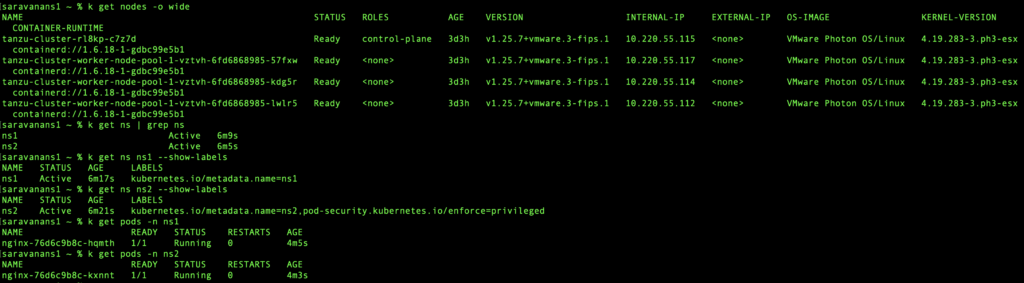
As you can see from the “k get nodes” output, the nodes were running v1.25.7. I had created two namespaces “ns1” and “ns2” for the purposes of demonstration. One of the two namespaces is labelled, as you can see from the “k get ns ns2 –show-labels” output. I have set it to enforce=privileged, which means no workloads in the namespace would be rejected.
After upgrade
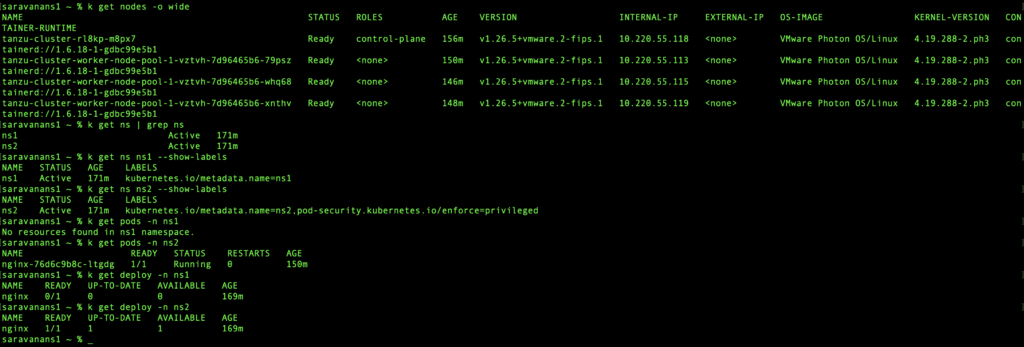
And there you go, pod in ns1 goes missing while the one in ns2 got recreated. Let’s explore what’s wrong with the pod in ns1.
If you look at the screenshot, you would notice that the deployment in ns1 is in a not ready state. Let us go ahead and describe the replica set associated and find out what the problem is.
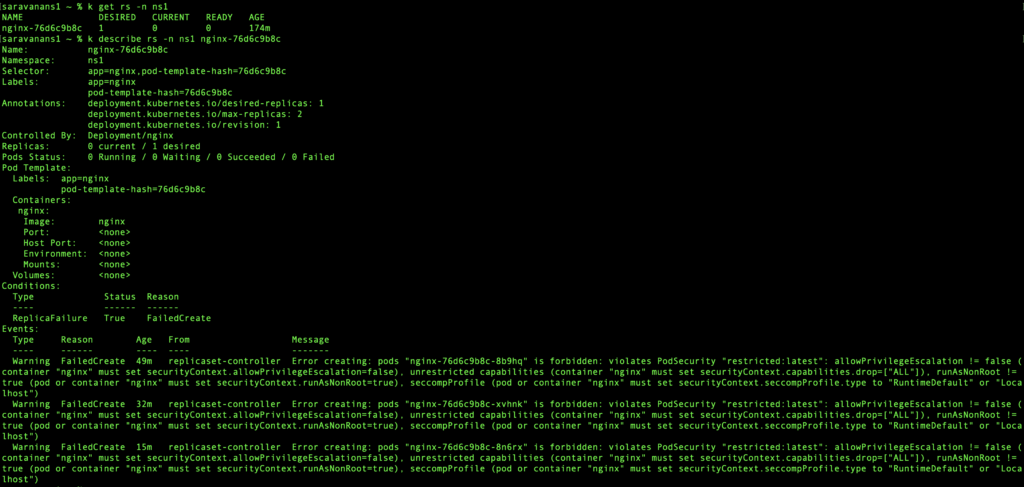
There it is. The pod creation failed because it violates PodSecurity “restricted:latest”. Since there is no label on the namespace ns1, it uses the default PSA which is “enforce=restricted” and prevents the pod from coming up since it doesn’t comply with pod security standards.
Also, a point to note here is that the pod security is applied only to the pod objects and not the workload object (ex: deployment/job) that is used to create the pod.
Workaround
On the namespace, where the replica set controller is complaining about violation, apply the name space label post migration.
kubectl label --overwrite ns ns1 pod-security.kubernetes.io/enforce=baseline
Once the label is applied, our pod should be running after the replica set controller initiates the reconciliation. That’s it folks. Good luck with your upgrades!
Happy learning!